분산 환경에서 Zipkin을 활용한 요청의 전체 흐름을 추적해봅시다!
📌 들어가기
마이크로서비스 아키텍처는 독립적으로 배포되고 관리되는 작은 서비스들이 모여 애플리케이션을 구성하게 됩니다. 이러한 환경에서는 서비스 간의 통신이 빈번하게 발생하며, 각 서비스가 독자적인 로그를 남기기 때문에 전체 트랜잭션의 흐름을 파악하기가 어렵습니다. 예를 들어, 주문 서비스 -> 결제 서비스 -> 배송 서비스 등의 여러 서비스가 순차적으로 호출되는 과정에서 각 서비스는 별도의 로그를 각자 남기기 때문에 어떤 서비스에서 문제가 발생했는지 확인하기 어렵습니다.
이러한 문제점 때문에 분산 트레이싱은 문제 발생 시 원인을 신속하게 파악하고, 성능 병목을 찾아내는 데 필수적인 도구로 등장합니다.
본 포스트에서는 분산 트레이싱 도구 중 Zipkin을 활용한 분산 트레이싱을 다루도록 하겠습니다.
마이크로서비스 환경의 복잡성
마이크로서비스 아키텍처에서는 하나의 사용자 요청이 여러 서비스를 거치며 처리됩니다. 주문, 결제, 배송 서비스 등 여러 서비스를 거치게 되는 것이죠. 이러한 분산된 호출 구조는 여러 문제점을 유발할 수 있습니다.
각 서비스마다 별도의 로그를 남기기 때문에 하나의 트랜잭션이 어디에서 지연되거나 장애가 발생했는지 확인하기 어렵습니다. 그리고 전체 흐름에서 어느 부분이 응답 시간을 지연시키는지도 파악하기 어렵습니다.
모놀리식(Monolihic)의 경우 하나의 서비스로 애플리케이션이 구동되기 때문에, 전체 흐름에 대한 로그를 하나의 서비스에서 디버깅 할 수 있습니다. 하지만 MSA에서는 문제를 파악하기 위해 관련된 모든 서비스들의 로그를 하나하나 다 살펴봐야 하는 번거로움이 존재합니다.
만약 분산 트레이싱 도구가 없다면, 위와 같은 문제를 해결하기 위해 각 서비스에서 개별적으로 로그를 분석해야 하며, 이는 시간 소모적이이고 비효율적일 뿐만 아니라, 문제 진단의 어려움이 따르기 때문에 신속하게 대응하지 못할 위험이 높아집니다.
Zipkin을 활용한 요청 추적
Zipkin은 오픈 소스 분산 트레이싱 시스템으로, 마이크로서비스 환경에서 서비스 간 호출 흐름을 시각화하고 분석할 수 있도록 도와주는 도구입니다. Zipkin을 활용하면 각 서비스의 호출 데이터를 중앙에서 수집하여 아래 문제점들을 해결해줍니다.
- 전체 호출 흐름 시각화: 사용자 요청이 어떤 경로로 전달되는지 시각화하여 한 눈에 파악 할수 있도록 해줍니다.
- Latency 분석: 각 서비스 간 호출의 응답 시간 정보를 제공하여 어떤 서비스의 어떤 로직에서 성능 병목이 일어나는지 쉽게 식별할 수 있습니다.
- 장애 원인 분석: 트랜잭션 중 발생한 예외나 오류를 신속하게 탐지하고, 어느 서비스에서 문제가 발생했는지 분석 할 수 있습니다.
Zipkin 적용 방법
예전에는 Spring Boot 애플리케이션에 쉽게 분산 트레이싱 기능을 추가할 수 있도록 도와주는 Spring Cloud Sleuth라는 라이브러리를 사용했었습니다. 하지만 최근 버전으로 업데이트 되면서 Spring Cloud Sleuth는 Deprecated 될 라이브러리가 되었습니다. 따라서 최근 버전에서는 Micrometer로 분산 트레이싱 기능을 추가하도록 변경되었습니다.
Dependency
1 | |
application.yml
1 | |
- 여기서
spring.application.name은 서비스 태깅에 활용되며, 각 서비스의 이름이 Zipkin UI에 표시되어 호출 흐름을 쉽게 파악할 수 있습니다. - 위와 같이 의존성과 설정을 마치면, 자동으로 각 요청에 고유한 Trace ID와 Span ID를 부여하여, 서비스 간의 호출 관계를 추적하게 됩니다.
분산 트레이싱의 핵심 개념: TraceId와 SpanId
분산 시스템에서 요청 추적을 가능하게 하는 핵심 요소는 TraceId와 SpanId입니다. 이 두 식별자는 B3 Propagation 형식의 기반이 되며, 전체 시스템에서 요청 흐름을 추적하는 데 필수적입니다.
TraceId
TraceId는 하나의 완전한 트랜잭션 흐름을 식별하는 고유 식별자입니다. 사용자 요청이 시스템에 처음 들어올 때 생성되며, 해당 요청이 여러 서비스를 거치더라도 동일한 TraceId가 유지됩니다. 일반적으로 128비트(16바이트) 길이의 랜덤 값으로 생성되며, 16진수 문자열로 표현됩니다.
예: 4bf92f3577b34da6a3ce929d0e0e4736
SpanId
SpanId는 전체 트레이스 내에서 특정 작업 단위(Span)를 식별하는 고유 식별자입니다. 하나의 트레이스는 여러 개의 스팬으로 구성되며, 각 스팬은 서비스 내 호출이나 서비스 간 통신 같은 작업을 나타냅니다. SpanId는 일반적으로 64비트(8바이트) 길이이며, 역시 16진수 문자열로 표현됩니다.
예: a2fb4a1d1a96d312
서비스 간 통신에서 SpanId의 값은 변경되지만, 부모-자식 관계를 유지하기 위해 이전 SpanId는 ParentSpanId로 저장됩니다. 이를 통해 Zipkin과 같은 시스템에서 요청 처리 흐름을 계층적으로 시각화할 수 있습니다. 추가로 트레이싱 식별자(TraceId, SpanId)들이 Kafka 메시지와 함께 전파됨으로써, 비동기 메시징 환경에서도 일관된 트레이싱 컨텍스트를 유지할 수 있습니다.
Zipkin UI를 활용한 트레이스 분석
서비스 간 호출 흐름 시각화
Zipkin UI는 수집된 트레이스 데이터를 기반으로, 서비스 간 호출 흐름을 직관적으로 시각화해줍니다. 개발자는 UI를 통해 각 서비스가 호출한 순서와 관계를 그래픽으로 확인할 수 있습니다. 또한 특정 트랜잭션의 세부적인 스팬 정보와 타임라인을 분석할 수도 있습니다.
Latency 분석 및 장애 감지
Zipkin UI에서는 각 스팬의 응답 시간을 시각적으로 표시하여, 어느 부분에서 지연이 발생했는지 쉽게 식별할 수 있습니다. 이를 통해 성능 병목 구간을 찾아내고, 장애 발생 시 원인 분석에 필요한 정보를 제공합니다. 만약 이러한 시각화 도구가 없으면, 로그 파일만으로 각 서비스 간의 호출 관계와 지연 시간을 분석해야 하므로, 문제 발생 시 즉각적인 대응이 어려워질 것입니다.
Spring AOP를 활용한 미들웨어 간의 요청 추적
마이크로서비스에서는 HTTP 호출 외에도 Kafka, Redis와 같은 미들웨어를 활용하는 경우가 많습니다. Zipkin과 Micrometer의 기본 의존성과 설정만으로는 미들웨어 통신 경로를 자동 추적하진 않습니다. 미들웨어간의 호출 흐름까지 추적하기 위해, 추적에 필요한 로직을 스프링 AOP를 활용하여 사용자 정의 트레이싱 코드를 삽입할 수 있었습니다.
예를 들어, 스프링 AOP를 활용하여 Kafka를 통한 메시지 발행/구독 흐름도 추적할 수 있습니다. 이를 통해 메시지 큐를 통한 비동기 호출도 명확하게 추적할 수 있으며, 메시지 손실이나 지연 문제를 쉽게 추적할 수 있습니다.
만약 이러한 미들웨어 추적 메커니즘이 없다면, 각 미들웨어 간의 호출 흐름이 단절되어 문제 발생 시 원인 파악에 큰 어려움이 따를 것입니다. 이는 디버깅 하는 시간이 급격히 증가할 수 있습니다.
Server → Kafka 메시지 트레이싱
이제, 실제로 사이드 프로젝트에서 Spring AOP를 활용하여 Zipkin B3 트레이싱을 Kafka 메시지에 적용하는 방법을 살펴보겠습니다.
스프링 애플리케이션에서 Kafka로 메시지를 발행할 때, 현재의 트레이싱 컨텍스트를 메시지 헤더에 포함시켜 전달하는 것이 중요합니다. 이를 위해 AOP(Aspect-Oriented Programming)를 활용하면 기존 코드를 수정하지 않고도 이 기능을 깔끔하게 추가할 수 있습니다.
KafkaTemplate.send(String, Object) 메서드를 인터셉트하여 ProducerRecord에 B3 헤더를 추가하는 방식으로 트레이싱 컨텍스트를 전파할 수 있습니다. 이렇게 하면 Kafka 소비자가 메시지를 처리할 때 동일한 트레이싱 컨텍스트를 유지할 수 있어, Zipkin에서 전체 요청 흐름을 연속적으로 확인할 수 있게 됩니다.
1 | |
- Spring의
@Aspect기능을 활용하여KafkaTemplate.send(String, ..)메서드 호출을 인터셉트합니다. 이를 통해 메시지가 Kafka로 전송되기 직전에 트레이싱 정보를 주입할 수 있는 지점을 확보합니다. - 인터셉트 시점에 Brave Tracer API를 통해 현재 활성화된 트레이싱 컨텍스트(TraceId, SpanId, Sampling 여부 등)를 추출하고, 이를 Kafka의 ProducerRecord 헤더에 B3 형식(X-B3-TraceId, X-B3-SpanId, X-B3-Sampled)으로 인코딩하여 추가합니다.
- 이렇게 트레이싱 정보가 포함된 메시지를 소비자 서비스에서 처리할 때, 메시지 헤더에서 B3 정보를 추출하여 동일한 트레이싱 컨텍스트를 복원합니다. 이를 통해 Zipkin과 같은 분산 트레이싱 시스템에서 서비스 간 경계를 넘어 하나의 연속된 트랜잭션으로 시각화하고 분석할 수 있게 됩니다.
⭐️ 이 방식의 가장 큰 장점은 애플리케이션 코드를 직접 수정하지 않고도 트레이싱 컨텍스트 전파를 구현할 수 있어, 관심사 분리(Separation of Concerns) 원칙을 준수하면서 분산 시스템의 가시성을 높일 수 있다는 점입니다.
Kafka → Server 트레이싱
Kafka 메시지를 소비하는 측에서는 메시지 헤더에 포함된 B3 트레이싱 정보를 추출하여 서버 처리 과정의 트레이싱에 연결해야 합니다. 이 과정 역시 AOP를 활용하면 깔끔하게 구현할 수 있습니다.
@KafkaListener 어노테이션이 적용된 메서드를 인터셉트하여 ConsumerRecord에서 B3 헤더 정보를 추출하고, 이를 기반으로 새로운 스팬을 생성하는 방식으로 구현됩니다. 이렇게 하면 소비자 서비스에서의 처리 과정이 기존 트레이싱 컨텍스트와 연결되어 하나의 흐름으로 추적됩니다.
1 | |
이 Aspect는 다음과 같은 핵심 기능을 수행합니다:
@KafkaListener어노테이션이 적용된 메서드를 타겟으로 하는 Pointcut 정의- ConsumerRecord 객체에서 B3 헤더 추출을 위한 커스텀 extractor 구현
- 추출된 트레이싱 컨텍스트를 기반으로 새로운 스팬 생성
- 생성된 스팬의 컨텍스트 내에서 원래 메서드 실행
- 메서드 실행 중 발생하는 예외를 스팬에 기록
- 메서드 실행 완료 후 스팬 종료
이러한 방식으로 구현하면, Kafka 메시지 소비 시점에서 자동으로 트레이싱 컨텍스트가 복원되어 MDC(Mapped Diagnostic Context)에 반영됩니다. 이를 통해 로그에 traceId가 자동으로 포함되어 로그 추적이 용이해지며, Zipkin과 같은 분산 트레이싱 시스템에서도 하나의 트랜잭션으로 시각화됩니다.
참고로, ELK 스택을 이용한 중앙집중식 로그 모니터링 시스템에 관한 포스트도 있습니다. 짧게 소개하자면, Kibana에서 TraceId를 검색하면 여러 서버에서 분산적으로 발생한 로그 전부를 타임스탬프(timestamp)순으로 확인할 수 있습니다.
아래 이미지는 주문 생성, 결제 승인, 배달 접수, 주문 완료 등 여러 이벤트 처리에 대한 kafka 비동기 처리 도입에도 사용자의 한 요청에 대한 모든 흐름이 트레이싱 되고 있는 것을 확인할 수 있었습니다:
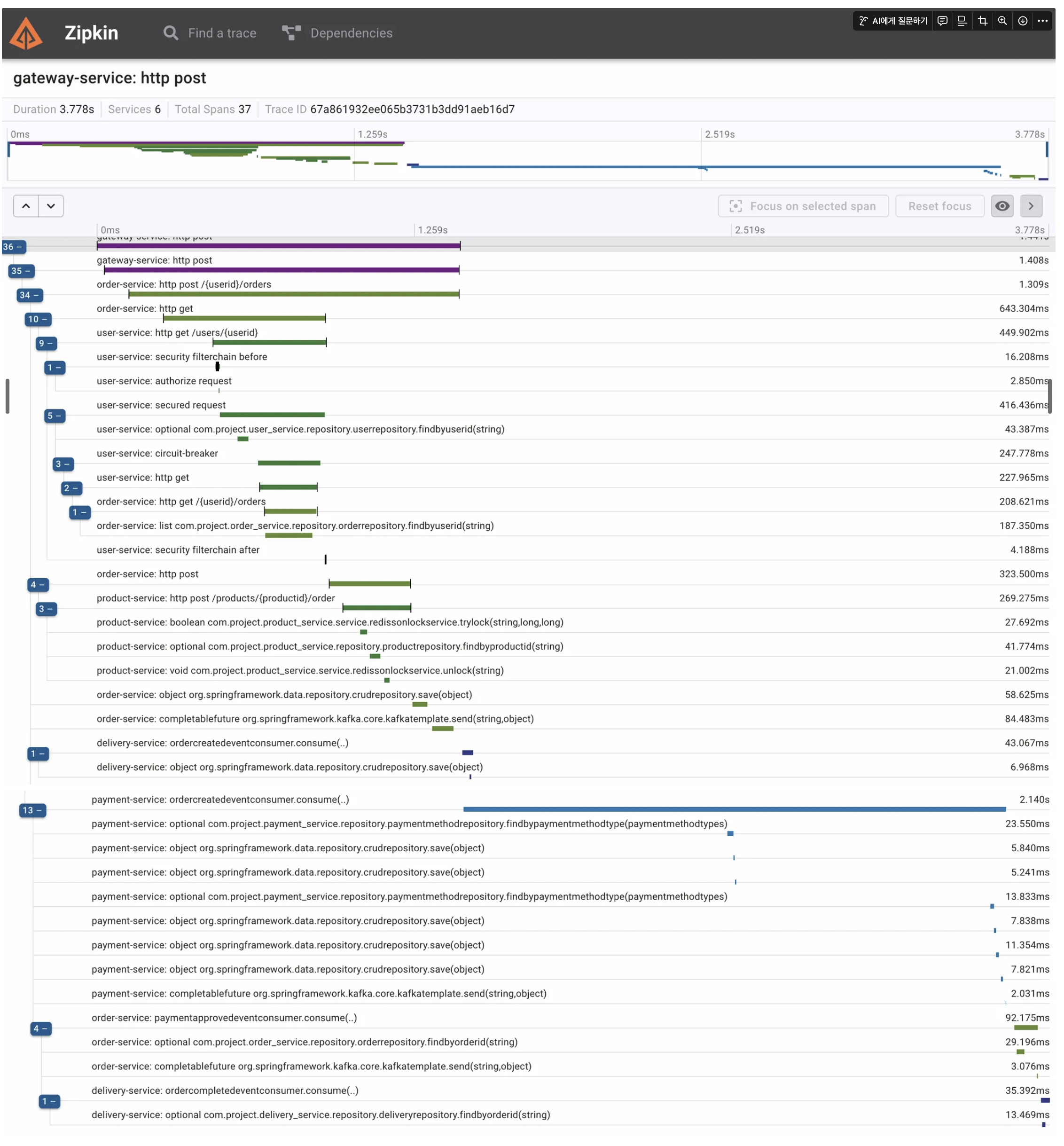
user service, order service, product service, delivery service, payment service 각 서버마다 이벤트 발행과 구독을 처리하는 흐름이 모두 담겨 있습니다.
트레이싱 컨텍스트 전파의 이점
이러한 방식으로 트레이싱 컨텍스트를 전파함으로써 얻을 수 있는 주요 이점은 다음과 같습니다:
- End-to-End 가시성: 사용자 요청부터 모든 서비스를 거쳐 최종 응답까지의 전체 흐름을 하나의 트레이스로 확인 가능
- 성능 병목 식별: 전체 트랜잭션에서 지연이 발생하는 지점을 정확히 식별 가능
- 장애 추적 용이성: 오류 발생 시 관련된 모든 서비스의 로그를 쉽게 연관지어 분석 가능
- 코드 침습성 최소화: AOP를 활용하여 비즈니스 로직과 트레이싱 로직의 명확한 분리 유지
이러한 접근 방식은 마이크로서비스 아키텍처에서 특히 유용하며, 서비스 간 메시지 전달이 빈번한 분산 시스템의 관찰성(Observability)을 크게 향상시킵니다.
🚀 결론
마이크로서비스 아키텍처에서는 서비스 간 호출 흐름이 복잡해짐에 따라, 단순 로그 분석만으로는 문제의 원인을 파악하기 어렵습니다. Zipkin과 Micrometer를 활용하면, 전체 트랜잭션의 흐름을 시각화하고 각 서비스의 성능을 모니터링할 수 있어 문제 발생 시 신속하게 대응할 수 있습니다. 이러한 도구들이 없다면, 시스템 장애나 성능 병목을 찾아내는 데에 많은 시간과 리소스가 소모되며, 이는 비즈니스에 심각한 영향을 미칠 것입니다. MSA 환경에서 Zipkin을 통한 분산 트레이싱은 단순히 로그를 남기는 것을 넘어, 시스템의 전체적인 건강 상태를 관리하고, 장애 발생 시 신속한 원인 분석 및 대응 전략을 마련하는 데 필수적인 요소라 볼 수 있습니다.