마이크로서비스 아키텍처에서 ELK(Elasticsearch + Logstash + Kibana) 스택을 활용한 중앙 집중식 로그 모니터링에 대해 알아봅시다!
📌 들어가기
최근 마이크로서비스 아키텍처가 널리 사용되면서, 다양한 서비스에서 발생하는 로그를 효과적으로 수집 및 분석할 수 있는 방법이 필요해졌습니다. 마이크로서비스 환경에서는 각 서비스마다 별도의 로그 파일이 생성됩니다. 개별 서버마다 분산되어 저장된 로그 파일을 일일이 분석하는 것은 매우 고된 일이 될 것입니다. 그리고 문제 발생 시 신속하게 로그를 추적하여 원인을 파악하고 대응하는 데에 많은 시간이 소모될 것입니다. 이처럼 MSA 환경에서 로그를 중앙 집중식으로 관리하지 않는다면 여러 가지 문제가 발생할 수 밖에 없습니다.
이에 따라 ELK(Elasticsearch + Logstash + Kibana)를 활용한 중앙 집중식 로그 모니터링의 필요성이 더욱 부각되고 있습니다.
본 포스트에서는 ELK 스택 기반의 로그 모니터링 구성과, Zipkin 로그 트레이싱과의 연계를 통한 효율적인 모니터링 방법에 대해 살펴보도록 하겠습니다. Zipkin 로그 트레이싱과 관련한 포스트가 있으니 참고하시면 좋을 것 같습니다.
ELK 도입의 효과
Logstash를 통한 로그 수집 및 필터링
Logstash는 다양한 소스의 로그를 실시간으로 수집하고, 필터링 및 가공하여 일관된 포맷으료 변환해줍니다. 이를 통해 수집된 로그의 품질을 높이고, 분석의 효율성을 높일 수 있습니다. 개인 사이드 프로젝트에서는 각 서비스가 로그 파일을 각 서버가 저장하도록 했고, 해당 로그 파일을 Logstash가 수집하도록 설정했습니다.
Elasticsearch 기반의 빠른 검색
Elasticsearch는 분산형 검색 엔진으로, 대용량 로그 데이터를 빠르게 인덱싱 및 검색할 수 있습니다. 덕분에 서비스 장애 시 빠른 속도의 로그 검색으로 인하여 문제를 신속하게 대응할 수 있게 됩니다.
Kibana 대시보드를 통한 시각화
Kibana는 Elasticsearch에 저장된 로그 데이터를 시각화하여 대시보드를 구성할 수 있게 해줍니다. 이를 통해 로그의 흐름과 이상 징후를 한눈에 파악할 수 있으며, 실시간 모니터링 환경을 구축할 수 있습니다.
Logback과 ELK 연동 및 구성 방법
Logback이란?
스프링 부트는 로깅 시스템의 기본 구현체로 Logback을 사용하도록 설정되어 있습니다. 기본적인 성능과 기능이 좋기 때문에 많이 사용되고 있습니다. 만약 설정을 커스텀하고 싶다면 logback.xml 파일로 설정을 조정하실 수도 있습니다.
스프링 부트 프로젝트에서 개발 편의성을 위해 Lombok을 대부분 사용하실 겁니다. 해당 라이브러리에는 Slf4j(Simple Logging Facade For Java)라는 로그 시스템에 대한 추상화 계층을 제공하는 인터페이스가 존재합니다. Slf4j의 기본 구현체는 Logback으로 설정되어 있습니다. Slf4j 자체는 인터페이스이므로 로깅을 수행하지 않고, 실제 로깅을 수행하는 구현체(ex: Logback, Log4j 등)에게 위임합니다. 만약 로깅 구현체를 교체하고 싶다면, 의존성을 변경함으로써 쉽게 교체할 수 있습니다.
Logback -> Logstash 로그 전송
logback 로깅 시스템을 통해 Logstash로 로그를 전송하기 위해선 다음 의존성부터 추가해줘야 합니다. 그런 다음 logback.xml 설정에 Logstash로 로그를 출력하는 Appender를 추가해주면 됩니다.
1 | |
아래 XML 설정은 스프링 애플리케이션에 설정된 logback.xml 설정입니다. 해당 설정은 실시간으로 발생되는 로그를 콘솔, 파일, Logstash에 각각 출력하는 설정입니다.
1 | |
참고로 Logstash 의 기본 Port는 5044로 구동됩니다. 사이드 프로젝트에서 도커로 Logstash를 구동하여 실습을 진행했습니다.
위 처럼 설정을 마치면 이제 스프링 애플리케이션의 로깅 시스템(Logback)이 자동으로 로그를 Logstash 로 전송할 것입니다.
Logstash -> Elasticsearch 로그 저장
Logstash는 단순히 데이터 파이프라인 역할만 하기 때문에, 결국 로그를 저장할 데이터베이스가 필요합니다. 여기서 Elasticsearch가 로그를 저장하는 역할을 맡게 됩니다. 엘라스틱서치는 앞서 말했듯이, 대용량 로그 데이터를 빠르게 인덱싱 및 검색할 수 있습니다. 덕분에 찾고자 하는 로그를 빠르게 탐색할 수 있게 되는 것이죠.
아래는 Logstash의 설정 파일입니다. 애플리케이션 -> Logstash (수집) -> Elasticsearch (저장)처럼 일련의 데이터 파이프라인의 설정 값입니다. 이를 Logstash를 구동시킬 때 설정해주어야 하는 값입니다.
1 | |
- input: 해당 설정으로 데이터를 입력받겠다는 정보를 나타냅니다. (TCP 5044, JSON 포맷으로 데이터 입력 받음.)
- output: 출력하고자 하는 엘라스틱서치 저장소의 정보를 적어줍니다.
- hosts: 엘라스틱서치의 호스트 정보를 적어줍니다. 위 설정은 동일한 도커 네트워크 상에서 구동되고 있는 환경이기 때문에 도커 컨테이너명을 사용했습니다.
- index: 엘라스틱서치의 어떤 인덱스에 저장할 지 명시해줍니다. (RDBMS의 테이블명이라고 보시면 됩니다.)
위 처럼 logstash.conf 파일을 설정했다면, 이제 Logstash가 수집한 로그 데이터를 Elasticsearch 저장소로 전송할 것입니다.
만약, Logstash를 도커로 구동하신다면 아래 도커 컴포즈 파일처럼 logstash.conf 파일을 볼륨 마운팅 해주셔야 합니다.
1 | |
Elasticsearch -> Kibana 로그 데이터 시각화
이제 Elasticsearch에 로그 데이터가 적재된다면, Kibana를 활용하여 로그 데이터를 시각화할 수 있습니다.
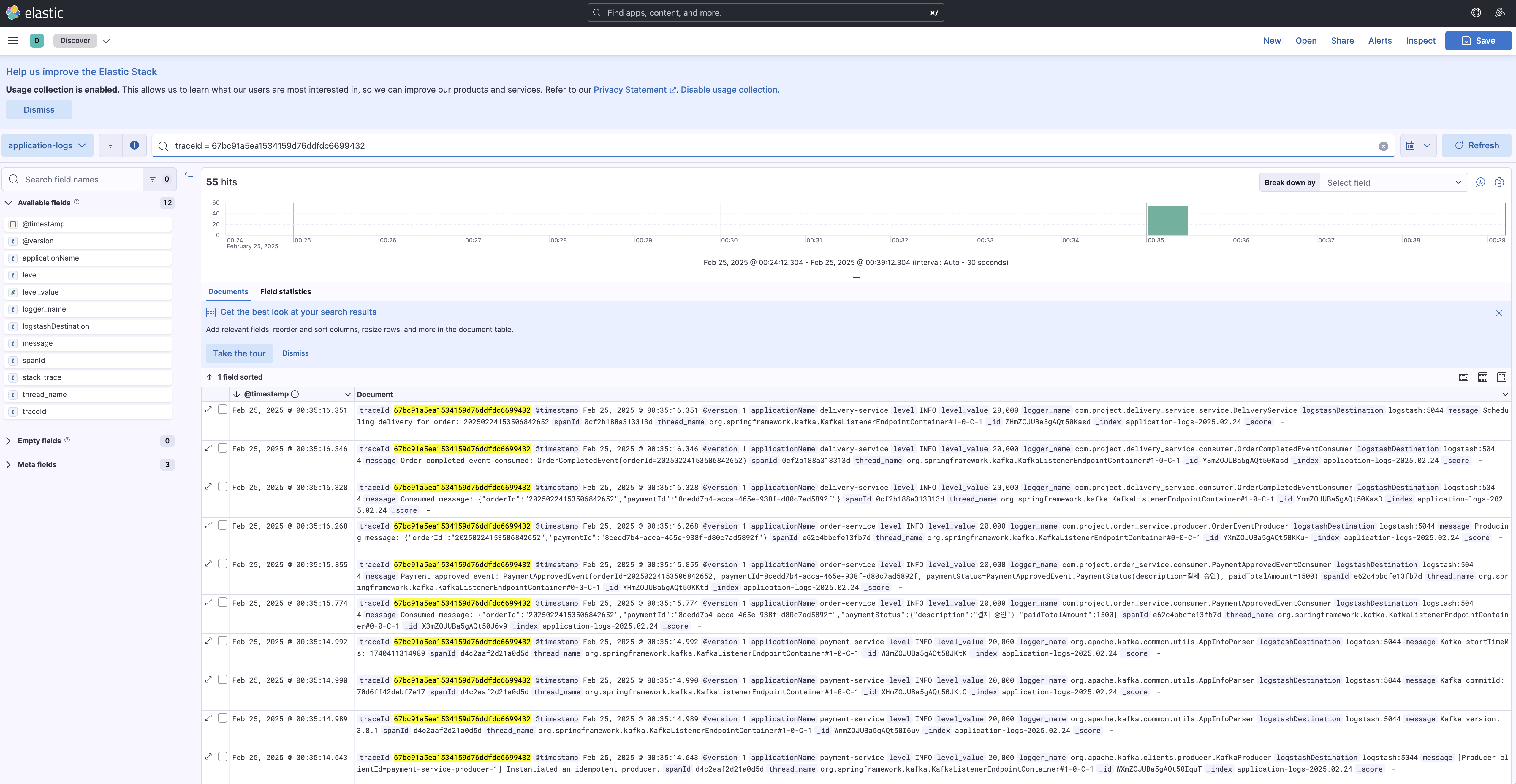
이때 Zipkin을 활용한 분산 로그 트레이싱을 통합 적용한다면, 여러 서비스에 걸쳐 처리될 때 발생하는 로그의 흐름을 추적할 수 있도록 도와줍니다. 각 요청에 고유한 TraceID를 부여하여, 여러 서비스에 분산되어 기록된 로그들을 Elasticsearch에서 하나의 흐름으로 연결지어 검색할 수 있습니다.
Kibana의 Discovery 서비스에서 TraceID를 입력하면 해당 요청에 관련된 모든 로그가 타임스탬프 순서대로 정렬시켜 모니터링 할 수 있습니다. 이를 통해 단일 요청이 서비스 전반에서 어떻게 처리되었는지 한눈에 파악할 수 있게 됩니다.
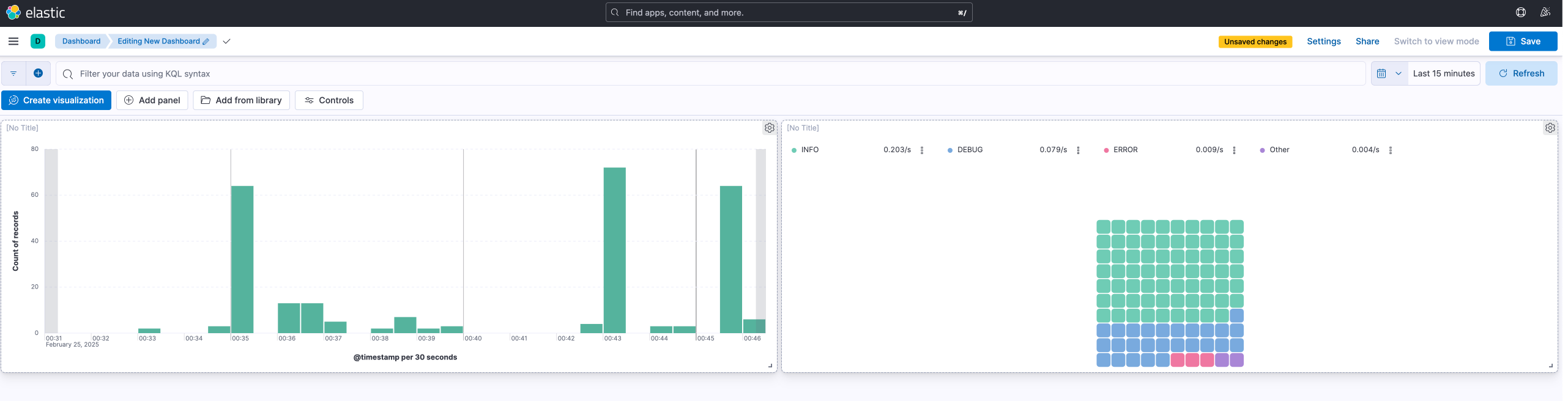
또한, 로그 레벨의 분류를 통해 전체 로그에 대한 통계를 대시보드로 확인도 가능합니다.
🚀 결론
ELK 스택을 기반으로 한 중앙 집중식 로그 모니터링은 MSA 환경에서 필수적인 요소라고 생각합니다. 분산된 로그를 한눈에 파악할 수 없는 문제를 해결해주고, 실시간 모니터링 대응 능력을 향상시켜줌과 동시에, Zipkin과의 통합을 통해 요청의 전체 흐름을 추적할 수 있다는 점은 시스템 운영의 효율성을 크게 향상시킬 수 있습니다. ELK스택과 Zipkin과 같은 도구들을 적절히 활용한다면, 장애 발생 시 빠른 원인 분석과 문제 해결이 가능해져, 전체 서비스의 안정성 유지에 기여할 수 있을 것입니다.
이상으로 ELK 스택과 Zipkin 통합을 통한 중앙 집중식 로그 모니터링의 필요성과 장점에 대해 알아보았습니다. 본 포스트를 참고하여 여러분의 환경에 맞는 최적의 로그 관리 시스템 구축에 도움이 되었으면 좋겠습니다. 감사합니다.