Read Phenomena
여러 트랜잭션이 동시에 실행된다면 데이터를 읽어들일 때마다 값이 변할까?
변화된 값을 읽는게 좋을까 아니면 일관된 값을 읽어들이는 것이 좋을까?
사실, 정답은 없지만 일관된 값을 읽어들이는 것이 더 바람직하다.
트랜잭션이 동시에 수행되면서 여러 가지 읽기 현상들이 존재하는데 이것을,
Read Phenomena 라고 한다.
여러 트랜잭션이 수행되더라도 예상되고 바람직한 결과를 얻기 위해서 트랜잭션 간 고립성(Isolation)이 필요한 것이다.
Dirty Reads
Dirty 의 의미는 데이터가 완전히 flush 되지 않았거나 완전히 commit 되지 않았다는 것을 의미한다. 즉, 다른 트랜잭션이 쓴 내용을 읽지만 실제로 아직 커밋되지 않은 것을 읽는 현상을 말한다.
Non-repeatable Reads
트랜잭션 내에서 어떤 데이터를 읽은 이후, 동일한 자원을 다시 읽으려고 할 때 그 값이 변경되어져 있는 현상을 말한다.
Phantom Reads
범위의 해당하는 값을 읽어들이는 쿼리가 있을 때, 첫 번째 범위 쿼리로부터 얻었던 결과에 없었던 값이 두 번째 범위 쿼리에는 새로운 행이 삽입되어 처음에는 없던 값을 읽는 현상을 말한다. 즉, 다른 트랜잭션의 쓰기 작업으로 인해 처음에 읽지 않았던 것을 두 번째 쿼리에서 읽게 된 것을 말한다.
Lost Updates
한 트랜잭션 내에서 수정한 데이터 값을 커밋하기 전에 다른 트랜잭션이 커밋 전의 데이터를 읽는 현상을 말한다. 결국 커밋 이후 시점에서 보면 다른 트랜잭션은 과거의 데이터를 읽어버린 꼴이다.
Dirty Reads 예시
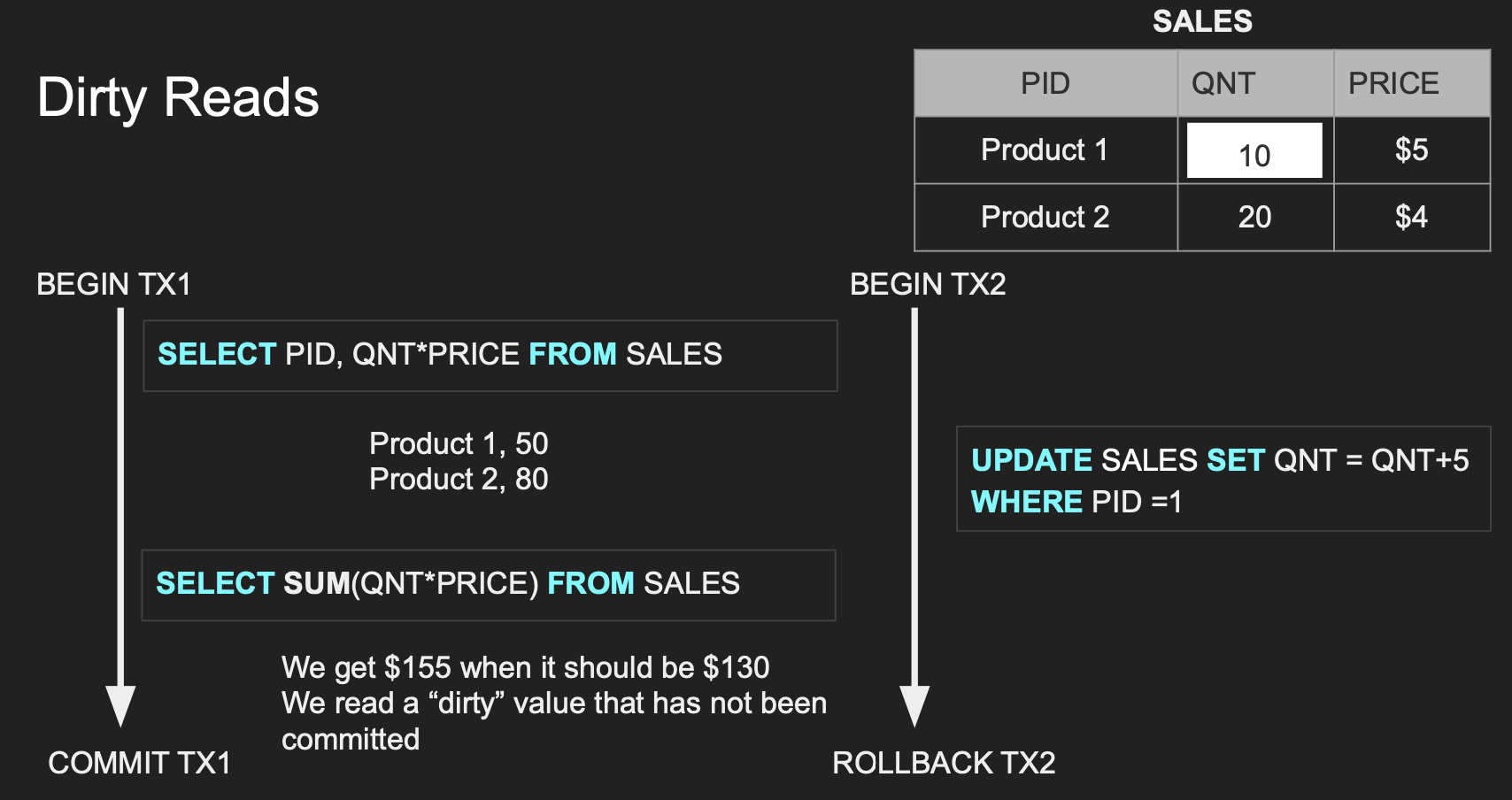
- TX1 Read => (Product1, 50), (Product2, 80)
- TX2 Update => Product1이 5개가 더 팔려서
QNT5개를 추가하였다.(10 -> 15) - TX1 Read => TX2의 커밋되지 않은 값을 읽어서 155 합의 결과를 도출했다. (일관성이 있으려면 사실 130이라는 합이 나왔어야 했다.)
- TX2 Rollback => TX2의 롤백으로 인해 결국 TX1이 읽은 155값(Dirty Value)에 대한 원인도 사라진 셈이다.
Non-repeatable Read 예시
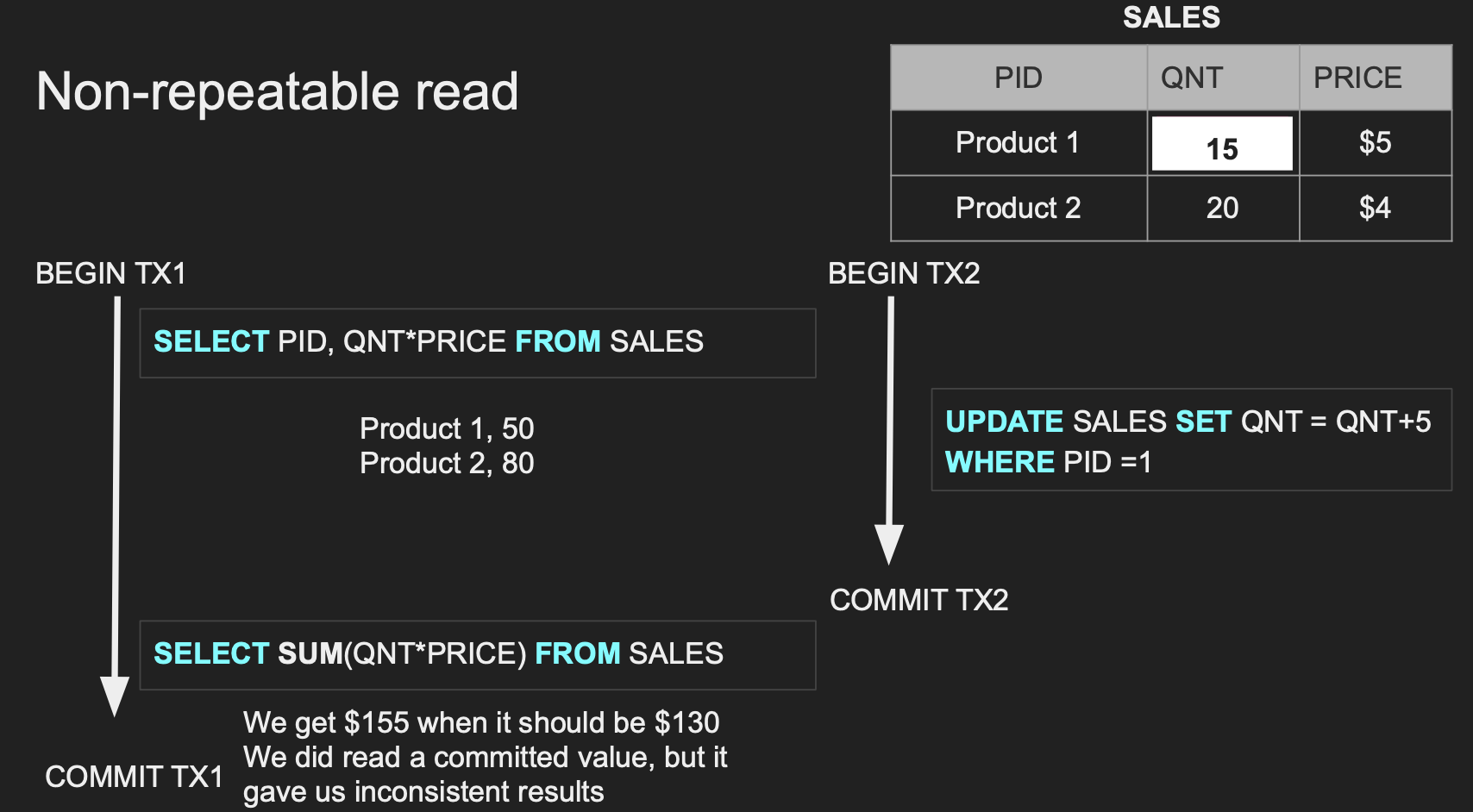
- TX1 Read => (Product1, 50), (Product2, 80)
- TX2 Update => Product1이 5개가 더 팔려서
QNT5개를 추가하였다.(10 -> 15) - TX2 COMMIT
- TX1 Read => TX2 커밋 이후 read 했기 때문에 Dirty Value를 읽어들인 것은 아니다. 하지만 여전히 일관성이 깨진 155이라는 합을 내놓고 있다.
비즈니스 요구사항과 성능 사이의 trade-off 를 고려했을 때, Non-repeatable read를 허용하더라도 문제가 생기지 않는 상황이라면 Non-repeatable read를 허용할 수도 있다.
Phantom Read 예시
Phantom Read(유령 읽기)는 범위 쿼리에서 발생한다. 특히 where 절이 존재할 경우 유령읽기가 발생하지 않을 수 있는 예시를 생각해 내기 어려울 정도로 흔하게 발생 가능한 현상이다.
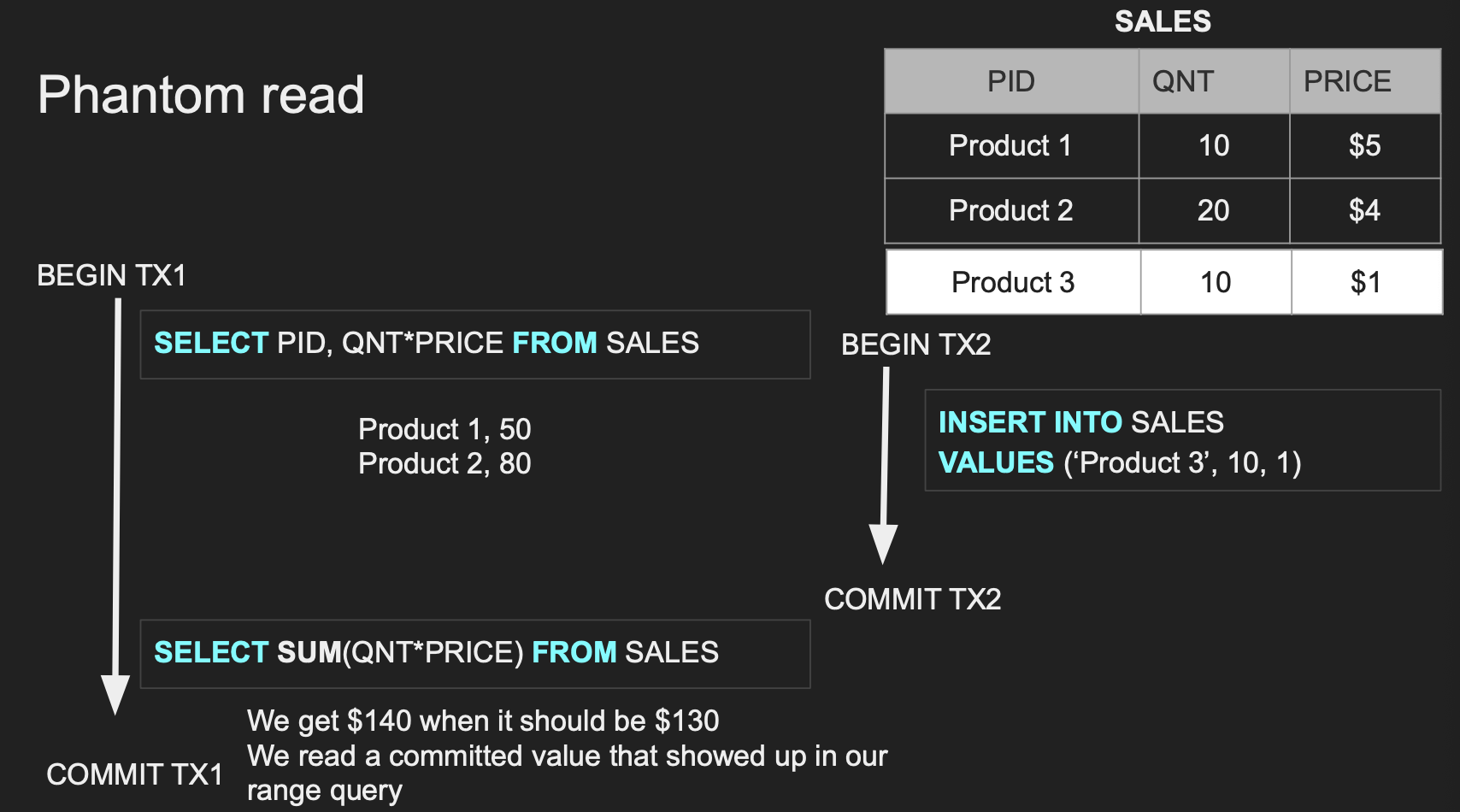
- TX1 Read => (Product1, 50), (Product2, 80)
- TX2 Insert => (Product3, 10개, 1$) 새로운 상품 삽입
- TX2 COMMIT
- TX1 Read => 새로 삽입된 행까지 조회하기 때문에 일관성이 깨진 $140의 값을 도출한다.
Non-repeatable Read VS Phantom Read
반복되지 않는 읽기는 기존에 읽었던 데이터가 그 다음에 읽을 때 일관성이 깨지는 경우이고, 유령 읽기는 기존에 없던 데이터가 그 다음에 읽을 때 새로 생기는 데이터 때문에 일관성이 깨지는 경우이다.
Lost Updates 예시

- 두 개의 트랜잭션 TX1, TX2가 거의 동시에 BEGIN하여 둘 다 Product1의
QNT를 10으로 바라본다. - TX1 Update => Product1의 QNT에 10을 더한다. (10 -> 20)
- TX2 Update => Product2의 QNT에 5를 더한다. (10 -> 15)
- TX2 COMMIT => TX1에서 업데이트한 값이 TX2이 업데이트한 값으로 덮어쓰여졌다.
- TX1 Read => TX1이 업데이트한 값을 토대로 $180 값을 얻어야 하지만 TX2의 덮어쓰기로 인해 TX1의 업데이트 값을 잃어버리고 일관성이 깨진 $155 값을 얻게 되었다.
일관성(Consistence)에 도달하기 위해
한 트랜잭션 내에서 읽는(read) 데이터들의 값들은 일관성(consistence)이 유지되길 기대한다. 다시 말해, 한 트랜잭션 내에서 특정 데이터에 대해 100번의 조회를 하더라도 100번 전부 같은 값을 얻을 수 있어야 한다는 것이다. 쉽게 생각하면 다른 트랜잭션의 영향없이 본인 트랜잭션 내에서만 데이터 정보가 일관되어야 한다고 볼 수 있다. 하지만 실제 시스템은 여러 트랜잭션이 동시에 실행된다. 여기서 우리는 일관성을 얻기 위해 고립이 필요한 것이다.
Isolation Levels
Isolation Level(격리 수준)을 구현하는 방식은 각 DBMS마다 다르다.
성능과 데이터의 일관성, 둘 사이의 trade-off를 고려하여 고립 수준을 정하면 된다.
Read Uncommitted
- 고립이 전혀 없는 단계이다. 커밋 여부에 상관없이 다른 트랜잭션에 의해 발생된 변화가 즉각적으로 보여진다.
Dirty read가 발생하기 때문에 일관성이 깨진 값을 조회할 수 있다.- 트랜잭션의 처리 속도는 가장 빠르다. 데이터를 처리할 때 트랜잭션 간 어떠한 제약도 없기 때문이다.
Read Committed
- 한 트랜잭션 안의 각 쿼리들은 다른 트랜잭션이 커밋 완료된 변화들만 볼 수 있다.
- 커밋된 변경사항만 읽지만, Non-Repeatable Read 와 같은 일관성이 깨질 수도 있다.
Repeatable Read
- 트랜잭션이 실행되는 동안 쿼리가 행을 읽을 때, 해당 행이 변경되지 않도록 트랜잭션이 보장한다.
- 반복되지 않는 읽기(Non-repeatable Read)를 해결하기 위해 고안된 격리 수준이다.
- 동일한 트랜잭션 내에서는 값을 몇 번이나 읽든 항상 같은 값을 읽게 된다.
Snapshot
- 트랜잭션의 각 쿼리는 트랜잭션 시작 시점까지 커밋된 변경 사항만 볼 수 있다. 이것은 그 순간의 데이터베이스 스냅샷 버전의 데이터를 읽는 것과 같다.
- PostgreSQL의
Repeatable Read는Snapshot격리 수준으로 동작한다. - 트랜잭션이 시작하면 타임 스탬프로 버전을 표시한 스냅샷을 생성하고 트랜잭션이 실행중에 항상 해당 버전 스냅샷의 데이터들을 읽게 된다. 이로써 유령 읽기를 해결할 수 있다.
Serializable
- 트랜잭션은 하나씩 차례대로 직렬화된 것처럼 실행된다.
- 모든 Read Phenomena 현상들이 사라진다.
- 속도가 가장 느린 격리 수준이다.
Snapshot vs Serializable
Snapshot Isolation
트랜잭션이 시작될 때 데이터베이스의 스냅샷(데이터 읽기 전용 복사본)을 생성한다. 트랜잭션 동안 모든 읽기 작업은 이 스냅샷을 기준으로 수행되며, 트랜잭션이 수행되는 동안 다른 트랜잭션의 변경사항을 보지 않는다.
특징
Non-blocking reads: 읽기 작업은 다른 틀내잭션의 쓰기 작업을 차단하지 않는다.Non-blocking writes: 쓰기 작업은 다른 트랜잭션의 읽기 작업을 차단하지 않는다.Write Skew: 두 트랜잭션이 동시에 같은 데이터를 업데이트하려 할 때 충돌이 발생할 수 있으며, 이는 쓰기 스큐(write skew) 현상으로 이어질 수 있다. 이는 데이터 불일치 문제를 유발할 수 있다.
사용 사례
많은 읽기 작업이 필요하지만 약간의 쓰기 스큐를 허용할 수 있는 시스템에서 사용된다.
Serializable Isolation
트랜잭션이 직렬적으로(즉, 순차적으로) 실행된 것처럼 보이도록 보장한다. 이는 트랜잭션 간의 완전한 격리를 보장하며, 한 트랜잭션이 다른 트랜잭션의 중간 상태를 보지 않도록 한다.
특징
Strict isolation: 가장 높은 수준의 격리를 제공하며, 트랜잭션 간의 상호 간섭을 방지한다.Locking: 일반적으로 잠금(Locking)을 사용하여 동시성을 제공한다. 이로 인해 잠금 경합(lock contention)이 발생할 수 있으며, 이는 성능 저하로 이어질 수 있다.No anomalies: 읽기 스큐, 유령 읽기, 반복되지 않는 읽기와 같은 이상 현상을 방지 한다.
사용 사례
데이터 일관성이 매우 중요하고 트랜잭션 간의 충돌을 허용할 수 없는 시스템에서 사용된다.
주요 차이점
동시성: Snapshot 격리 수준은 높은 동시성을 제공하지만, 쓰기 스큐와 같은 데이터 불일치 문제를 유발할 수 있다. Serializable 격리 수준은 동시성을 제한하지만, 데이터 일관성을 반드시 보장한다.잠금: Serializable 격리 수준은 잠금을 사용하여 트랜잭션 간의 간섭을 방지하는 반면, Snapshot 격리 수준은 스냅샷을 사용하여 동일한 데이터를 읽는 동안에도 트랜잭션이 서로 간섭하지 않도록 한다.성능: Snapshot 격리 수준은 일반적으로 성능이 더 우수하며, 특히 읽기 작업이 많은 환경에서 더욱 효과적이다. 반면, Serializable 격리 수준은 잠금 경합으로 인해 성능이 저하될 수 있다.
요약
Snapshot 격리 수준은 높은 동시성을 제공하지만 일부 데이터 불일치 문제를 허용할 수 있는 환경에서 유용하며, Serializable 격리 수준은 데이터 일관성이 최우선인 환경에서 사용된다.
Isolation Levels vs Read Phenomena
아래 이미지는 격리 수준에 따른 Read Phenomena 발생 여부를 나타낸 표이다.
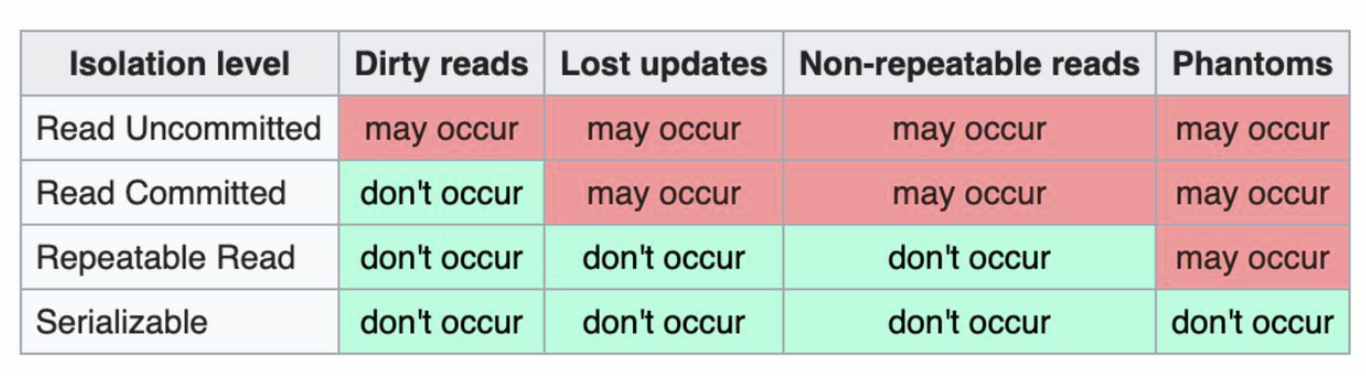
Snapshot level도 위 4가지 Read Phenomena 현상을 예방한다.
Database Implementation Of Isolation
각 DBMS는 격리 수준을 서로 다른 방식으로 구현한다.
데이터베이스 격리 수준을 구현하는 방식은 낙관적(Optimistic) 접근법과 비관적(Pessimistic) 접근법으로 나뉜다. 두 접근법은 트랜잭션 간의 동시성을 제어하는 두 가지 상반된 전략으로 구분된다.
비관적(Pessimistic) 접근법
트랜잭션이 충돌한 가능성이 있다고 가정하여, 데이터에 접근할 때마다 잠금을 걸어 충돌을 방지한다.
비관적(Pessimistic) 구현 방식은 동시성을 제어하는 것인데, 구체적으로 잠금(Lock)을 사용하는 방법이다.
row levle locks, table locks, page locks 등을 사용하여 Lost Updates를 예방할 수 있다.
락을 사용하는 것은 비용이 많이 들 뿐더러 다른 트랜잭션들이 대기 상태에 놓일 수 있기 때문에 성능 이슈를 야기할 수 있다.
특징
Lock-based: 데이터에 접근하는 시점에서 읽기 또는 쓰기 잠금을 설정하여 다른 트랜잭션이 동시에 동일한 데이터에 접근하지 못하게 한다.충돌 방지: 잠금을 통해 트랜잭션 간의 충돌을 미리 방지하며, 충돌이 발생할 가능성이 낮다.성능: 잠금으로 인한 오버헤드와 잠금 경합(lock contention)으로 인해 성능이 저하될 수 있다. 쓰기 작업이 많고 충돌 가능성이 높은 환경에서 적합하다.장점: 트랜잭션 간의 충돌을 효과적으로 방지할 수 있으며, 데이터 일관성을 보장한다.단점: 잠금으로 인한 교착 상태가 발생할 수 있으며, 높은 동시성을 제공하기 어렵다.
사용 사례
- 은행 거래 시스템
낙관적(Optimistic) 접근법
트랜잭션이 충돌하지 않을 것이라고 가정하여, 주로 트랜잭션 종료 시점에 충돌 검사를 수행한다.
낙관적(Optimistic) 구현 방식은 락을 사용하지 않기 때문에 다른 트랜잭션들이 대기하지 않으므로 비관적 방식에 비해 성능 부분의 이점이 있다. 많이 선호되는 방식이며 NoSQL 데이터베이스에서 선호되는 방식이다.
변경 사항들을 메모리에 유지했다가 트랜잭션 간 충돌이 발생하면 트랜잭션을 롤백시킨다. 이렇게 충돌하여 발생한 오류를 직렬화 오류라고 부른다.
특징
Lock-free: 데이터에 대한 접근 시점에서 잠금을 걸지 않으며, 대신 트랜잭션이 커밋되기 전까지 변경 사항을 추적한다.충돌 검사: 트랜잭션이 커밋될 때, 다른 트랜잭션이 동일한 데이터를 수정했는지 확인하고 충돌이 발생할 경우 트랜잭션을 롤백시킨다.성능: 읽기 작업이 많고 쓰기 작업이 상대적으로 적은 시스템에서 성능이 뛰어나다. 충돌이 적은 환경에서 특히 유리하다.장점: 높은 동시성을 제공하며, 잠금으로 인한 교착 상태(deadlock)가 발생하지 않는다.단점: 충돌이 빈번하게 발생하는 경우 롤백이 자주 일어나며, 이로 인해 오버헤드가 증가할 수 있다.
사용 사례
- 온라인 협업 도우 (예: Google Docs)
주요 차이점
- 잠금 방식
- 낙관적 접근법: 잠금을 사용하지 않으며, 트랜잭션 종료 시점에 충돌을 검사한다.
- 비관적 접근법: 데이터 접근 시점에 잠금을 설정하여 충돌을 방지한다.
- 충돌 처리
- 낙관적 접근법: 트랜잭션 종료 시점에 충돌을 검사하고, 충돌이 발생하면 롤백한다.
- 비관적 접근법: 잠금을 통해 충돌을 미리 방지한다.
- 동시성
- 낙관적 접근법: 높은 동시성을 제공하며, 읽기 작업이 많은 환경에 적합하다.
- 비관적 접근법: 잠금으로 인해 동시성이 낮아질 수 있으며, 쓰기 작업이 많은 환경에 적합하다.
- 성능
- 낙관적 접근법: 충돌이 적은 경우 성능이 뛰어나며, 교착 상태가 발생하지 않는다.
- 비관적 접근법: 잠금 경합으로 인해 성능이 저하될 수 있으며, 교착 상태가 발생할 수 있다.
요약
각 데이터베이스 시스템은 특정 격리 수준을 구현하는 방식에 따라 비관적 또는 낙관적 접근법을 사용할 수 있으며, 이는 시스템의 동시성 요구 사항과 성능 특성에 따라 다르다.
낙관적 접근법은 충돌이 드문 환경에서 높은 성능과 동시성을 제공하는 반면,
비관적 접근법은 데이터 일관성이 매우 중요하고 충돌 가능성이 높은 환경에서 안정성을 제공한다.
애플리케이션의 특성에 따라 적절한 접근법을 선택하는 것이 중요하다.